Neuroimaging Data Compression Part 2: Compression in the real world.
In a previous episode, we ran benchmarks on a variety of compression algorithms on a single nifti formatted neuroimaging file. The benchmarks we used did i/o from and to RAM, so as to allow better ‘theoretical’ comparisons of different compression algorithms. We decided that, while blosc and flzma2 got the best results, lzma2 is a commonly available option which realizes most of their gains over gzip.
Since that post went live, I’ve been working a lot with lzma2 (via tar with the -J option to use .tar.xz), and the performance is not quite what I’ve wanted. The compression ratios are just ok, and it takes a long time to compress (and doesn’t seem to use multicore). This may be because of limitations of the disk, or it could be because I’m compressing more than just one file at a time. It could also be because I’m not passing the right options to xz. So I wanted to run another round of comparisons. This time, I want to just run benchmarks in our analyis environment, using commonly available tools, and measuring performance of actual bash commands. I’m only going to evaluate gzip and lzma2 via xz (bzip2 is antiquated and the rest aren’t easily available. But there are a few other things I want to iterate over:
Sorting: I want to test a variety of sorting methods. In theory, we might get better compression if files that have similar patterns of data (e.g., event files) are compressed sequentially instead of interspersed amongst other types of files (e.g., images). This is controlled by the tar command, which globs all the files together before they are compressed. If the order is different, you can get different results – this can create differences in file size created by, for example, different versions of tar. Here are the different methods: * System: the default, just compress things in the order the system lists them. This may differ across run and system type. * Name: Sort alphabetically by name * Inode: Sort by position of the file on disk * Reverse: Reverse the filename like you were making a palindrome, then sort alphabetically by that list. Effectively, this sorts by file type given the file extensions present in BIDS. Tar can’t do this natively, you have to use a filelist, like so:
echo "Making a reverse filelist"
find $TARGET_DIRECTORY -type f > tmp/filelist
rev tmp/filelist | sort | rev > tmp/revfilelist
test_comp "gtar.rv.gz" "tar -czf $testarch -T tmp/revfilelist"
Threading: I want to test single threaded and 8 thread compression performance for xz. I might add a 4 core test later if that ends up being what we need.
Block Size: The way multithreading works in xz is that the file is split in to blocks, which are divied up among the processors. I read a blog post suggesting that changing the size of these blocks could optimize multithreading, which is attractive because I haven’t seen large performance differences from increasing the number of processors available to XZ.
Conclusions / tl; dr:
-
You can greatly accelerate tar.xz compression to something similar to what gzip can provide by using multithreading. However, with smaller datasets/sets of smaller files, you will need to tweak the block size parameter to realize full benefits.
-
You can improve your compression ratio and compression time a bit by controlling the order in which tar compresses files. The ideal way is by processing files in alphabetical order of the reversed lines. If you want something less cumbersome, simply passing –sort=“name” to your tar command will work almost as well. The improvements here are much smaller than what you get by using multithreading.
Here are some commands:
export XZ_OPT="-T8 --block-size=10486760"
tar --sort=name -cJf example.tar.gz target_dir
The best part of these optimizations is that they are not using exotic software: tar and xz are commonly installed on Linux and Mac systems. The flags I’m proposing do not in any way complicate decompression – a normal tar -xJf command will work equally well regardless of the options used to compress the file originally.
Generating the benchmarks.
I used an HTCondor job to compress the same set of files using 17 different methods. I did this once for a set of QC reports output by fmriprep (mostly as a pilot), and again using BIDS formatted raw data for one participant from the ABCD dataset. Finally, I ran the benchmarks for a full set of fmriprep outputs from one ABCD participant. I run the benchmarks 20 times to account for variability across run conditions. You can see the full script I used to do this on github, but the key part of the command is the usage of time to get processing time for each compression command:
# Outputs: realSeconds \t peakMem \t CPUperc
/usr/bin/time -f '%e \t %M \t %P' -ao tmp/timeout.txt
Here are a few lines from an example data file:
| Mlabel | realSeconds | peakMem | CPUperc | Ratio |
|---|---|---|---|---|
| gtar.df.ra | 1.89 | 3168 | 16 | 1 |
| gtar.df.gz | 4.70 | 3172 | 97 | 0.537 |
| gtar.in.gz | 4.65 | 3192 | 97 | 0.5371 |
| gtar.nm.gz | 4.62 | 3160 | 98 | 0.537 |
| gtar.rv.gz | 4.59 | 3092 | 98 | 0.5371 |
| gtar.df.xz | 57.17 | 97292 | 97 | 0.431 |
Inputs files
This dataset includes 4.3 GB of input files for one participant. This includes images in nifti format and some event files and supporting text documents.
I’ve omitted error bars when they are unhelpful. One interesting note is that some variability in compression occurs if you let the system sort the files for tar.
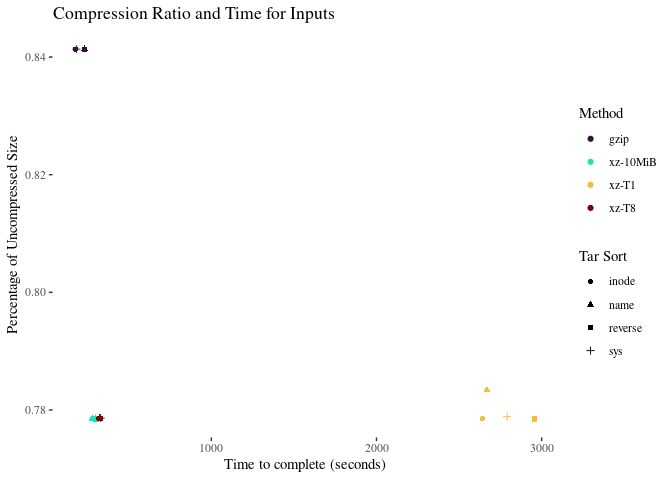
Multicore is very unambiguously helpful here. setting the block size helps a bit more. Let’s zoom in on the multicore xz options:
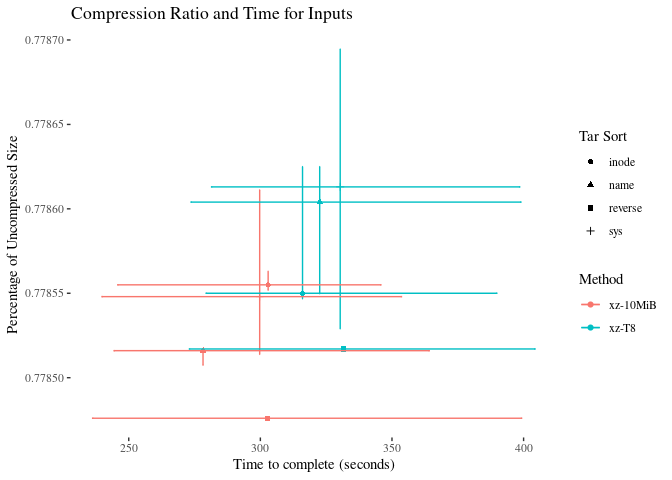
There is too much error to make firm conclusions about speed advantages. The ‘reverse’ sorting method is marginally better at compressing the data, but not by much. xz-10MiB still appears to be the best method.
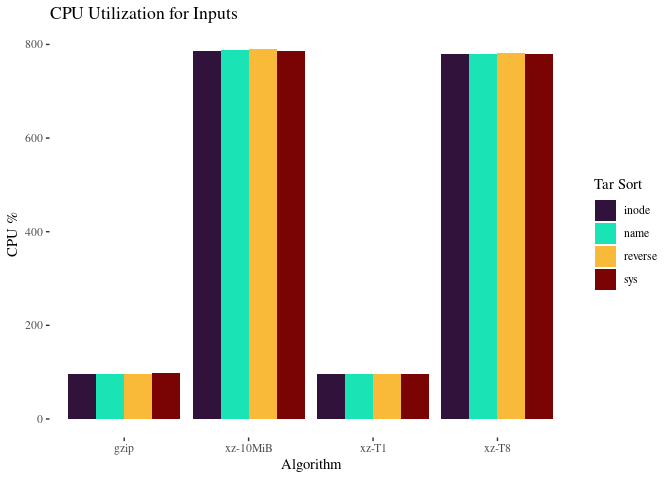
This explains why xz is so much faster with 10MiB blocks: it is doing a much better job using the 8 cores we provide for it.
fmriprep output
19 GB of output files including images in nifti format, CIFTI files, json, etc.
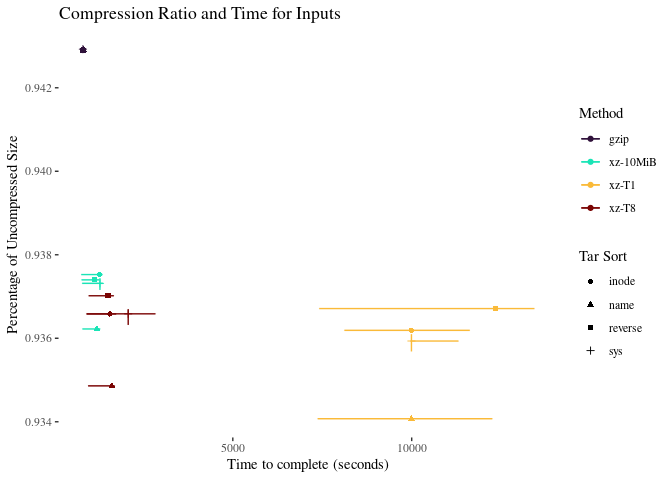
There’s a lot of variability in the timing, but xz-10MiB is marginally faster. Name sorted xz has the best compression, but there is actually very little compression available – possibly the outputs are already well compressed.
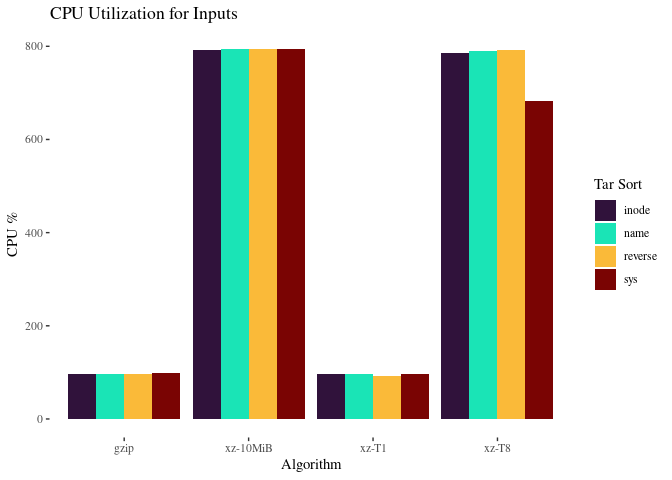
With so much data, we can use all of our processors regardless of block size, which explains why we don’t see much difference here.
QC data performance
This data file consists of 74 MB of mostly text: svg and html files composing a QC report for a typical subject.
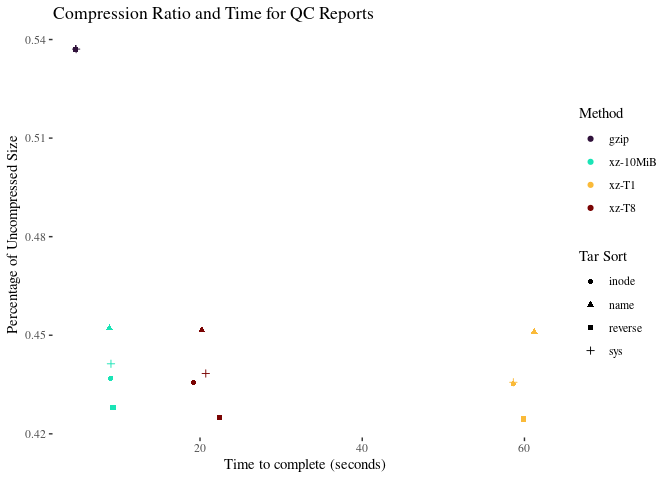
A couple of observations:
- XZ compression ratio does not depend very much on sorting or cores used. There might be a tiny loss of compression in the 10MiB, which is consistent with findings from the blog post linked above
- Reverse sorting the filenames before we compress them does give us a fraction of a percentage point more compression. After that, inode is a the second best.
This explains why xz is so much faster with 10MiB blocks: it is doing a much better job using the 8 cores we provide for it.
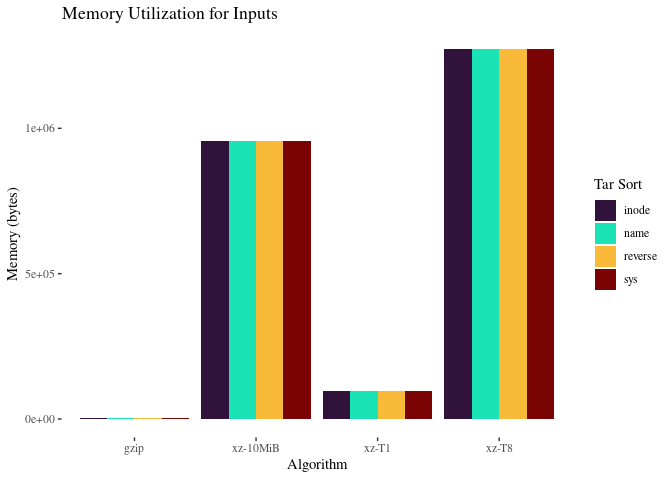
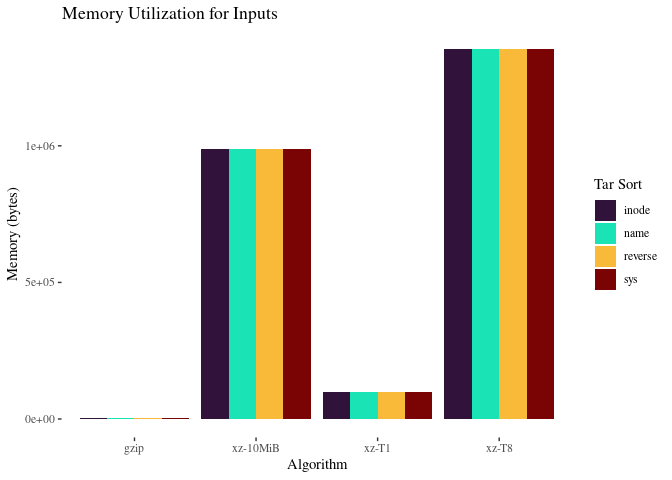
Again, the 10MiB jobs use more memory to get it done faster.